Written by Florent Scarpa, Data Scientist at Sustaain
Let’s talk today about a topic that moves calmly in the eye of the Gen AI hurricane: document information extraction. While some flashier topics steal the scene, information extraction silently benefits from the exponential progress of LLMs, multimodal models and agentic workflows.
Why document processing is still a tough task
In order to be on the same page, let’s clarify what we call document information extraction. It is a sub-domain of the more general task of information extraction, with a goal to automate the extraction of pre-defined key-value pairs from digital or scanned documents. For example, one may want to automatically extract and store in a database the name of customers and amounts payed from invoices.
Why do we and our clients think that such capabilities matter? While good ol’ documents are losing more and more territory to digital forms and the underlying databases, they still host a big chunk of the world’s data. And right now, we’re sitting at the junction between the paper and digital worlds. More and more data that used to be confined to documents is being dematerialized and structured into machine-readable databases. While this kind of necessary work used to be the burden of humans, we can all agree that reading and manually entering data from thousands of documents into a database is one hell of a time-consuming, brain-rotting task that we humans abhor.
How AI does the heavy lifting for Document Extraction
Such repetitive jobs definitely seem better off in the hands of an algorithm. However until recently, such task used to be too complex to be handled by “classical” algorithms. When you decompose it, the job consists in a mix of computer vision and natural language processing. Computer vision in the sense of Optical Character Recognition (OCR), whether the characters are printed or handwritten, and document layout comprehension such as tables, graphs. And natural language processing in order to understand the semantic content of the information captured by computer vision in order to extract the targeted data. This is why until recently, such tasks were quite burdensome to automate except for some big players that developed solutions on small, unflexible scopes. With the advent of LLMS, computer vision and VLMs, this has changed and made document information extraction much more accessible to everyone with sufficient tech background. Moreover, it made it possible to build tools with a much greater flexibility on extraction tasks, without having to start over every time and build swarms of expensive training/testing datasets.
Overcoming accuracy and consistency challenges
Nowadays, multimodal models, and in particular Visual Language Models (VLMs) allow everyone to just upload a document and asks questions about it. So it it enough to automate the question-answer process in order to automatically extract targeted document information from a collection? Not at all, and here is the reason: LLMs/VLMs answers widely vary in accuracy and completeness.
Even with newer, more specialized models or dedicated wrappers, testing extraction tasks often leads to disappointing results due to inconsistent accuracy and output quality. You will observe large quality disparities when asking the same question across different documents, or different questions of seemingly equal difficulty over the same document. In addition to that, no model can fully grasp the technical terminology or business-specific rules you intuitively apply when reading a document.
If you go one step further and search for more specialist tools, you can find as many “we solved document extraction” tools as there are containers in the world. However, in addition to the extremely variable quality of extractions, their usage is also at best difficult, or quite expensive. Defining specific extraction tasks, modifying them, adjusting details and infusing domain knowledge through prompt engineering is an extra workload where every change might break extraction performance over something unrelated.
Sustaain’s targeted solution to Bills of Lading and other transport documents
Here at Sustaain, we rode the LLM wave and quickly understood that simply waiting for better models would not make the cut. So we focused on one target: extracting fields from Bills of Lading (BLs) in order to bring the best of AI models, agentic workflows, domain knowledge and solve that one problem, but do it well.
For the non-connoisseur, BLs are used by carriers, mostly international container shipping lines, to acknowledge receipt of cargo for shipment. Such documents are at the core of international cargo transport operations, and some of their data often end up being entered manually into many proprietary softwares and databases. Commodity traders and operators typically waste hours manually writing such information into some software interface: transportation dates, ports of loading/discharge, BL and container numbers, detail and quantities of the shipment…


No miracle
When we started developing extraction solutions from available LLMs, we faced that wall of wrongness. Not only do LLMs read things wrong all the time (in particular serial numbers that have no semantic meaning), they often straight up hallucinate answers or do not find them at all.
Add to this scans of terrible quality where even a human being struggles to read information, and your VLM will fail to provide any interesting insight. Trying all the trendy “miracle” extraction softwares that are not much more than some VLM wrapped up with a restrictive prompt and some basic retry mechanism did not help any further.
Intelligence with guardrails
Basically, the rule of thumb is to think of LLMs/VLMs as very distracted interns that do not know the domain specifics yet, and try to read the document way too fast. In order to have those do a proper job, you need someone to micromanage them:
- cut the entire extraction task into separate atomic tasks, one field at a time
- explain the context clearly: what is a BL, what information does it contain; give specific instructions for specific templates with different layouts and vocabulary
- define the task even more clearly: describe exactly what information you want, in what format, where it can be found, provide examples that reflect the diversity of your sources
- enforce strict validation rules: if the output is a date or a container number, it should follow a specific format; if you are searching for the carrier company, provide the list of existing companies and make sure the answer is one of them; apply some consistency checks that allow to detect mistakes from business logic like the weight of the cargo being suspiciously low, or the date being too old
- when one extraction or method fails, do not despair and try another way; different models may perform better or worse on the same document, classical OCR libraries may sometimes shine where VLMs fail, twisting task prompts may change a failure into a success
Packaged and ready to ship
While that would be a lot of work for a human, it can be automated into a streamlined workflow that executes all those tasks without any human intervention. And that is exactly what we developed at Sustaain for BLs and other supply chain documents. This intelligence layer, built on top of high-performance GenAI models, allows us to overcome the shortcomings of those models: errors, hallucinations, lack of business understanding, lack of multi-page capability… Such a control layer allows use to provide extractions that are reliable enough to be used in production contexts with low human-in-the-loop requirements.
Moreover, in order to fit the infinite diversity of needs in information extraction tasks, we developed a nifty task definition interface that allows humans to define their own custom extraction tasks. This interface allows us to define any extraction task with a fine-grained control on task definition, output formatting and quality checks, all in one structured, human-readable text file that will be parsed by our system.
We also developed a large, diverse dataset of annotated document sources that we use to benchmark any new development in terms of global and specific performance metrics (machine learning specialists know that without such global performance-tracking processes, only quickly reaches a threshold where any targeted improvement may lead to catastrophic performance drops in other areas).
Document extraction API for full automation or graphic interface for human-in-the-loop validation
Because no system is perfect, we also developed an API that not only delivers the extraction contents, but also some analysis of the extraction quality. For all extracted content that did not pass a check, was not found in the document, or has a low confidence score, a relevant message will be added to the response so that the recipient may react accordingly.
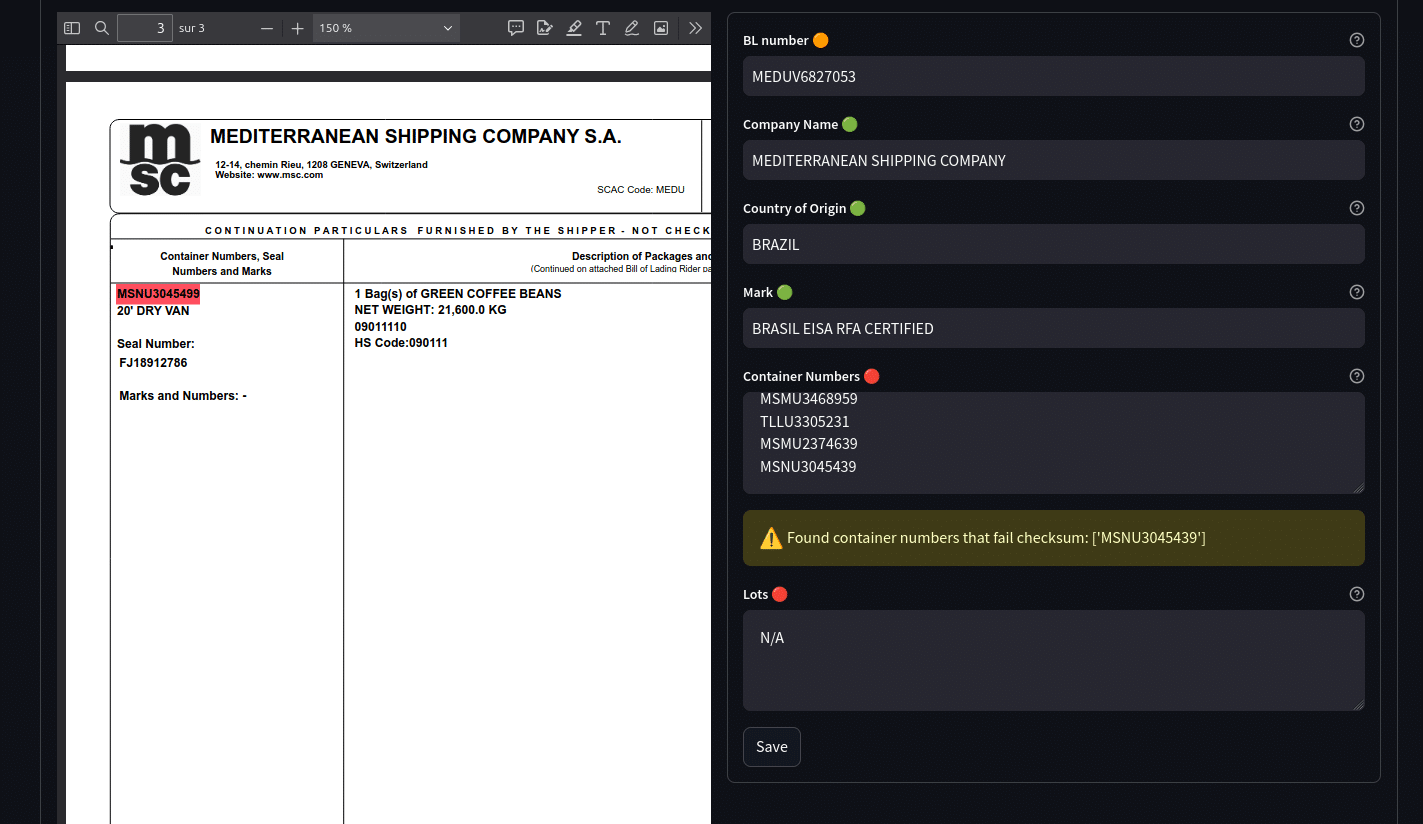
You may want to use our own user interface to upload documents, visualize quality warnings, and download extraction results. You can also connect your own systems to our API in order to do all those things yourself and fuel your own platforms with the extracted data batches.
Perfection is an ideal but that does not mean that we stop reaching for it. We keep refining our extraction workflows by enriching the control layer with smarter decision-making agents, testing newer models, and adding more business-relevant checks and rules. So if you are tired to copy some document data into your proprietary systems, feel free to contact us!